上一篇在分析 kubernetes 资源管理的过程中发现,Qos 中也有 cgroups 相关的操作,它们的作用又是什么呢,本篇来详细看下。
为什么需要 Qos
节点的 CPU 、内存等资源是有限的,如若不加于约束限止的话,Pod 之间会互相争抢资源最终影响服务稳定,于是就需要有一种机制来分级、隔离、限制它们,这就是 Qos。
Kubernetes 如何实现 Qos ?
怎样实现CPU、Memory等资源的隔离呢?Kubernetes 利用了 Kernel Cgroups 来实现Pod的Qos。
kubernetes Qos 类型
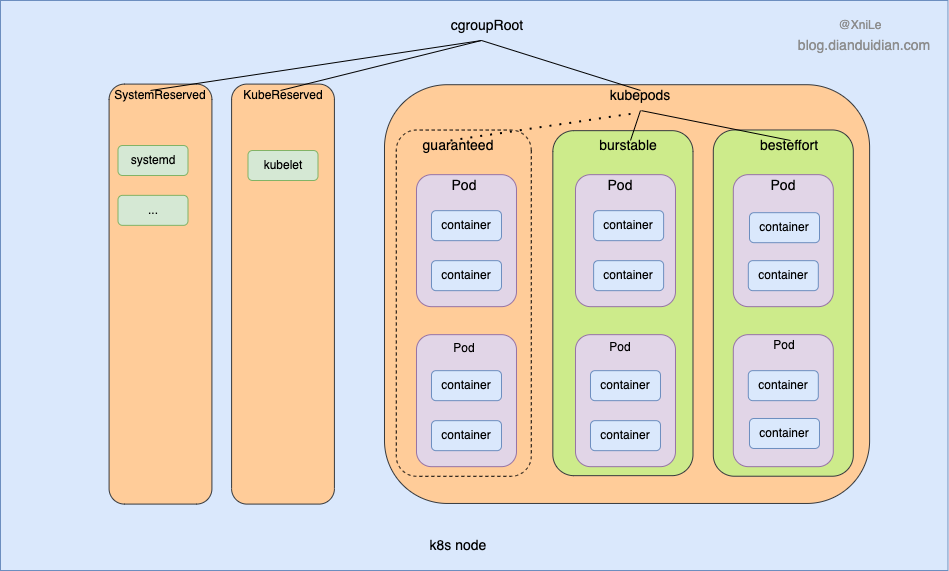
首先,kubernetes 给 Pod 定义了三种 Qos 类型:
- Guaranteed:Pod 里的每个容器都必须有内存/CPU 限制和请求,而且值必须相等。
- Burstable:Pod 里至少有一个容器有内存或者 CPU 请求且不满足 Guarantee 等级的要求,即内存/CPU 的值设置的不同。
- BestEffort:容器必须没有任何内存或者 CPU 的限制或请求。
三种Qos类型的优先级 Guaranteed > Burstable > BestEffort
有关Qos 类型的计算逻辑是在 GetPodQOS 函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
// GetPodQOS returns the QoS class of a pod.
// A pod is besteffort if none of its containers have specified any requests or limits.
// A pod is guaranteed only when requests and limits are specified for all the containers and they are equal.
// A pod is burstable if limits and requests do not match across all containers.
func GetPodQOS(pod *v1.Pod) v1.PodQOSClass {
requests := v1.ResourceList{}
limits := v1.ResourceList{}
zeroQuantity := resource.MustParse("0")
isGuaranteed := true
allContainers := []v1.Container{}
allContainers = append(allContainers, pod.Spec.Containers...)
allContainers = append(allContainers, pod.Spec.InitContainers...)
for _, container := range allContainers {
// process requests
for name, quantity := range container.Resources.Requests {
if !isSupportedQoSComputeResource(name) {
continue
}
if quantity.Cmp(zeroQuantity) == 1 {
delta := quantity.DeepCopy()
if _, exists := requests[name]; !exists {
requests[name] = delta
} else {
delta.Add(requests[name])
requests[name] = delta
}
}
}
// process limits
qosLimitsFound := sets.NewString()
for name, quantity := range container.Resources.Limits {
if !isSupportedQoSComputeResource(name) {
continue
}
if quantity.Cmp(zeroQuantity) == 1 {
qosLimitsFound.Insert(string(name))
delta := quantity.DeepCopy()
if _, exists := limits[name]; !exists {
limits[name] = delta
} else {
delta.Add(limits[name])
limits[name] = delta
}
}
}
if !qosLimitsFound.HasAll(string(v1.ResourceMemory), string(v1.ResourceCPU)) {
isGuaranteed = false
}
}
if len(requests) == 0 && len(limits) == 0 {
return v1.PodQOSBestEffort
}
// Check is requests match limits for all resources.
if isGuaranteed {
for name, req := range requests {
if lim, exists := limits[name]; !exists || lim.Cmp(req) != 0 {
isGuaranteed = false
break
}
}
}
if isGuaranteed &&
len(requests) == len(limits) {
return v1.PodQOSGuaranteed
}
return v1.PodQOSBurstable
}
|
Qos 都需要做什么呢?
习惯性从接口开始。
QOSContainerManager
看下 Qos manager 接口定义 QOSContainerManager
1
2
3
4
5
|
type QOSContainerManager interface {
Start(func() v1.ResourceList, ActivePodsFunc) error
GetQOSContainersInfo() QOSContainersInfo
UpdateCgroups() error
}
|
m.Start
我们来看下Start() 函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
func (m *qosContainerManagerImpl) Start(getNodeAllocatable func() v1.ResourceList, activePods ActivePodsFunc) error {
cm := m.cgroupManager
rootContainer := m.cgroupRoot
if !cm.Exists(rootContainer) {
return fmt.Errorf("root container %v doesn't exist", rootContainer)
}
// @xnile 创建 Qos 级cgroup /sys/fs/cgroup/<cpu,memory,...>/kubepods/<burstable,besteffort>/
// Top level for Qos containers are created only for Burstable
// and Best Effort classes
qosClasses := map[v1.PodQOSClass]CgroupName{
v1.PodQOSBurstable: NewCgroupName(rootContainer, strings.ToLower(string(v1.PodQOSBurstable))),
v1.PodQOSBestEffort: NewCgroupName(rootContainer, strings.ToLower(string(v1.PodQOSBestEffort))),
}
// Create containers for both qos classes
for qosClass, containerName := range qosClasses {
resourceParameters := &ResourceConfig{}
// the BestEffort QoS class has a statically configured minShares value
if qosClass == v1.PodQOSBestEffort {
minShares := uint64(MinShares)
resourceParameters.CPUShares = &minShares
}
// containerConfig object stores the cgroup specifications
containerConfig := &CgroupConfig{
Name: containerName,
ResourceParameters: resourceParameters,
}
// for each enumerated huge page size, the qos tiers are unbounded
m.setHugePagesUnbounded(containerConfig)
// check if it exists
if !cm.Exists(containerName) {
if err := cm.Create(containerConfig); err != nil {
return fmt.Errorf("failed to create top level %v QOS cgroup : %v", qosClass, err)
}
} else {
// to ensure we actually have the right state, we update the config on startup
if err := cm.Update(containerConfig); err != nil {
return fmt.Errorf("failed to update top level %v QOS cgroup : %v", qosClass, err)
}
}
}
// Store the top level qos container names
m.qosContainersInfo = QOSContainersInfo{
Guaranteed: rootContainer,
Burstable: qosClasses[v1.PodQOSBurstable],
BestEffort: qosClasses[v1.PodQOSBestEffort],
}
m.getNodeAllocatable = getNodeAllocatable
m.activePods = activePods
// @xnile 每隔1分种调用UpdateCgroups() 更新cgroups
// update qos cgroup tiers on startup and in periodic intervals
// to ensure desired state is in sync with actual state.
go wait.Until(func() {
err := m.UpdateCgroups()
if err != nil {
klog.InfoS("Failed to reserve QoS requests", "err", err)
}
}, periodicQOSCgroupUpdateInterval, wait.NeverStop)
return nil
}
|
主要作用:
- 负责创建
Burstable 和 BestEffort Qos level 的 cgroups 目录
- 每分钟调用一次 m.UpdateCgroups() 更新
cgroups
m.UpdateCgroups
继续看m.UpdateCgroups()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
|
func (m *qosContainerManagerImpl) UpdateCgroups() error {
m.Lock()
defer m.Unlock()
qosConfigs := map[v1.PodQOSClass]*CgroupConfig{
v1.PodQOSGuaranteed: {
Name: m.qosContainersInfo.Guaranteed,
ResourceParameters: &ResourceConfig{},
},
v1.PodQOSBurstable: {
Name: m.qosContainersInfo.Burstable,
ResourceParameters: &ResourceConfig{},
},
v1.PodQOSBestEffort: {
Name: m.qosContainersInfo.BestEffort,
ResourceParameters: &ResourceConfig{},
},
}
// 设置 cpu.shares
// update the qos level cgroup settings for cpu shares
if err := m.setCPUCgroupConfig(qosConfigs); err != nil {
return err
}
// 设置 hugetlb.<hugepagesize>.limit_in_bytes
// update the qos level cgroup settings for huge pages (ensure they remain unbounded)
if err := m.setHugePagesConfig(qosConfigs); err != nil {
return err
}
// cgroups v2 支持内存Qos,详细见 https://kubernetes.io/blog/2023/05/05/qos-memory-resources/
// update the qos level cgrougs v2 settings of memory qos if feature enabled
if utilfeature.DefaultFeatureGate.Enabled(kubefeatures.MemoryQoS) &&
libcontainercgroups.IsCgroup2UnifiedMode() {
m.setMemoryQoS(qosConfigs)
}
// 设置memory.limit_in_bytes,计算时还会根据 –qos-reserved string 配置的预留情况
if utilfeature.DefaultFeatureGate.Enabled(kubefeatures.QOSReserved) {
for resource, percentReserve := range m.qosReserved {
switch resource {
case v1.ResourceMemory:
m.setMemoryReserve(qosConfigs, percentReserve)
}
}
updateSuccess := true
for _, config := range qosConfigs {
err := m.cgroupManager.Update(config)
if err != nil {
updateSuccess = false
}
}
if updateSuccess {
klog.V(4).InfoS("Updated QoS cgroup configuration")
return nil
}
// If the resource can adjust the ResourceConfig to increase likelihood of
// success, call the adjustment function here. Otherwise, the Update() will
// be called again with the same values.
for resource, percentReserve := range m.qosReserved {
switch resource {
case v1.ResourceMemory:
m.retrySetMemoryReserve(qosConfigs, percentReserve)
}
}
}
// 使 Qos level 的 cgroups 配置生效
for _, config := range qosConfigs {
err := m.cgroupManager.Update(config)
if err != nil {
klog.ErrorS(err, "Failed to update QoS cgroup configuration")
return err
}
}
klog.V(4).InfoS("Updated QoS cgroup configuration")
return nil
}
|
-
准备 cpu.shares 配置。
这里需要注意一下,对于Qos level 级的cpu cgroup 只配置 cpu.shares,不会修改cpu.cfs_quota_us和cpu.cfs_period_us,即在这一层cgroup 不作 cpu 的限制。
-
准备 hugetlb.<hugepagesize>.limit_in_bytes 配置
-
准备内存 cgroups 配置,cgroups v2 支持内存 Qos,详细见 https://kubernetes.io/blog/2023/05/05/qos-memory-resources/
-
配置memory.limit_in_bytes,计算时还会根据 –qos-reserved string 配置的预留情况
-
最后调用 m.cgroupManager.Update 应用到 cgroups
函数主要是更新 Guaranteed、Burstable、BestEffort 三种Qos level 的 cgroups 配置。
QOSContainerManager.Start 何时启动?
启动调用栈:
Kubelet.Run -> Kubelet.updateRuntimeUp -> Kubelet.initializeRuntimeDependentModules -> ContainerManager.Start -> setupNode -> qosContainerManager.Start
oom_score_adj
不能忽略的一点,由于内核OOM killer机制的存在,当节点内存存在压力时内核会优先杀掉/proc/<pid>/oom_score值大的进程。
This file can be used to check the current score used by the oom-killer is for
any given . Use it together with /proc//oom_score_adj to tune which
process should be killed in an out-of-memory situation.
这个值是系统综合进程的内存消耗量、CPU时间(utime + stime)、存活时间(uptime - start time)和oom_adj(/proc//oom_adj)计算出的,消耗内存越多分越高,存活时间越长分越低。
oom_score_adj
The value of /proc//oom_score_adj is added to the badness score before it
is used to determine which task to kill. Acceptable values range from -1000
(OOM_SCORE_ADJ_MIN) to +1000 (OOM_SCORE_ADJ_MAX). This allows userspace to
polarize the preference for oom killing either by always preferring a certain
task or completely disabling it. The lowest possible value, -1000, is
equivalent to disabling oom killing entirely for that task since it will always
report a badness score of 0.
在计算最终的 badness score 时,会在计算结果是中加上 oom_score_adj ,这样用户就可以通过该在值来保护某个进程不被杀死或者每次都杀某个进程。其取值范围为-1000到1000 。
如果将该值设置为-1000,则进程永远不会被杀死,因为此时 badness score 永远返回0。
所以给Pod赋予相应的 oom_adj 权重,使Guaranteed 级别的Pod不会被优先 OOM Kill 掉,也是 Qos manager的一项重要职责。
关于oom_score_adj计算逻辑是在GetContainerOOMScoreAdjust
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
const (
// KubeletOOMScoreAdj is the OOM score adjustment for Kubelet
KubeletOOMScoreAdj int = -999
// KubeProxyOOMScoreAdj is the OOM score adjustment for kube-proxy
KubeProxyOOMScoreAdj int = -999
guaranteedOOMScoreAdj int = -997
besteffortOOMScoreAdj int = 1000
)
func GetContainerOOMScoreAdjust(pod *v1.Pod, container *v1.Container, memoryCapacity int64) int {
if types.IsNodeCriticalPod(pod) {
// Only node critical pod should be the last to get killed.
return guaranteedOOMScoreAdj
}
switch v1qos.GetPodQOS(pod) {
case v1.PodQOSGuaranteed:
// Guaranteed containers should be the last to get killed.
return guaranteedOOMScoreAdj
case v1.PodQOSBestEffort:
return besteffortOOMScoreAdj
}
memoryRequest := container.Resources.Requests.Memory().Value()
if utilfeature.DefaultFeatureGate.Enabled(features.InPlacePodVerticalScaling) {
if cs, ok := podutil.GetContainerStatus(pod.Status.ContainerStatuses, container.Name); ok {
memoryRequest = cs.AllocatedResources.Memory().Value()
}
}
oomScoreAdjust := 1000 - (1000*memoryRequest)/memoryCapacity
// A guaranteed pod using 100% of memory can have an OOM score of 10. Ensure
// that burstable pods have a higher OOM score adjustment.
if int(oomScoreAdjust) < (1000 + guaranteedOOMScoreAdj) {
return (1000 + guaranteedOOMScoreAdj)
}
// Give burstable pods a higher chance of survival over besteffort pods.
if int(oomScoreAdjust) == besteffortOOMScoreAdj {
return int(oomScoreAdjust - 1)
}
return int(oomScoreAdjust)
}
|
kubelet 与 Qos 相关的配置
–cgroups-per-qos Default: true
Enable creation of QoS cgroup hierarchy, if true, top level QoS and pod cgroups are created. (DEPRECATED: This parameter should be set via the config file specified by the kubelet’s --config flag. See kubelet-config-file for more information.)
–qos-reserved string
<Warning: Alpha feature> A set of <resource name>=<percentage> (e.g. “memory=50%”) pairs that describe how pod resource requests are reserved at the QoS level. Currently only memory is supported. Requires the QOSReserved feature gate to be enabled. (DEPRECATED: This parameter should be set via the config file specified by the kubelet’s --config flag. See kubelet-config-file for more information.)
总结
kubernetes 给 Pod分了三种 Qos 等级,分别为 Guaranteed、Burstable、BestEffort,主要依靠内核 cgroups 来完成资源限制,Qos manager 的作用就是负责创建、更新这三种 Qos level 级别的 cgoups 配置。
参考
https://cloud.tencent.com/developer/article/1583670
https://cloud.tencent.com/developer/article/2230267
https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/
https://kubernetes.io/docs/reference/config-api/kubelet-config.v1beta1/
https://docs.kernel.org/admin-guide/cgroup-v1/hugetlb.html
https://kubernetes.io/blog/2023/05/05/qos-memory-resources/